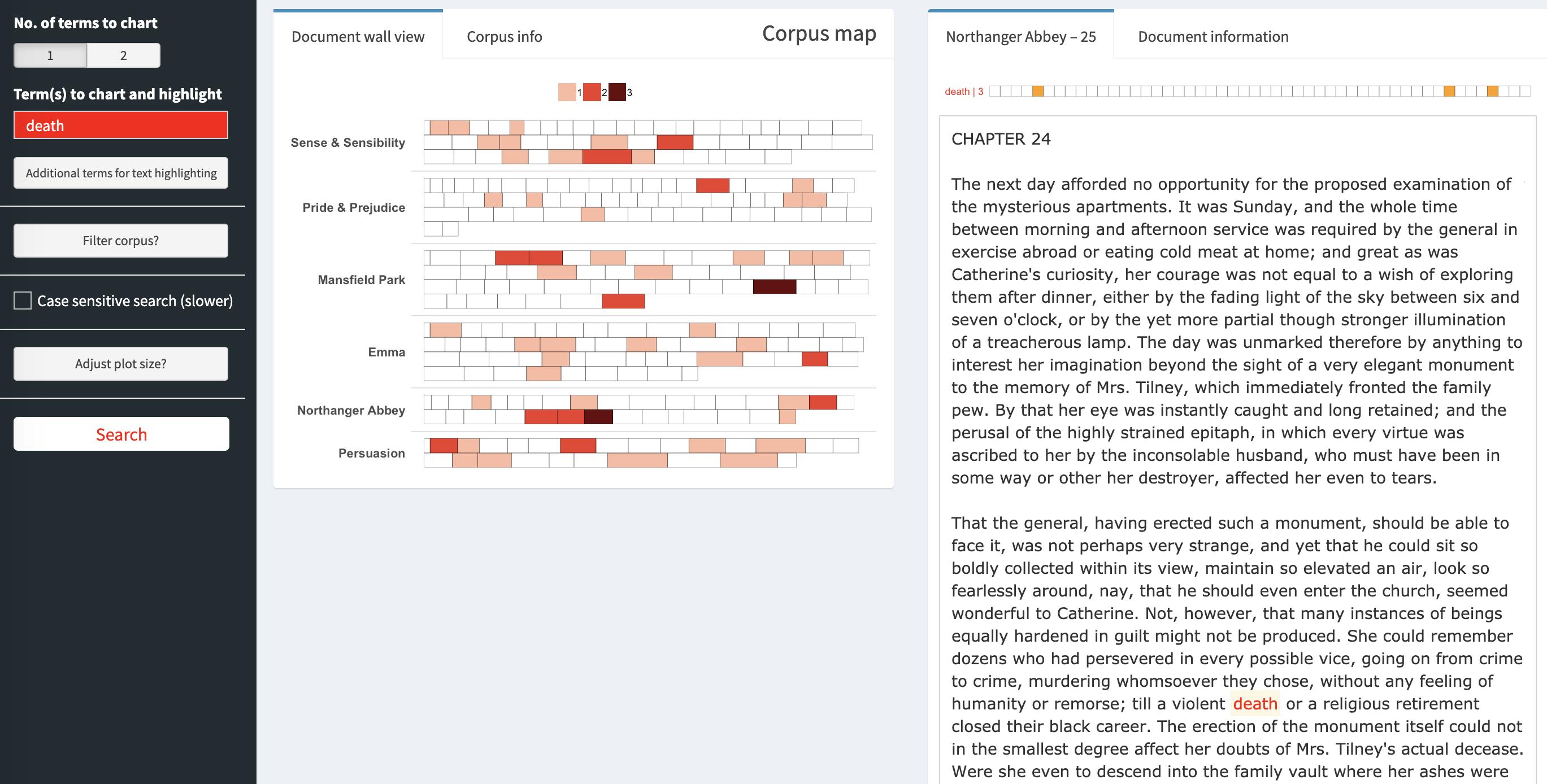
corporaexplorer can be used to explore not only chronological text collections with document date as main organising principle, but any collection of texts. The example used here: Jane Austen’s six novels, accessed through the janeaustenr package.
To run the Jane Austen demo app, run the following in the R console:
This app is created with the code below.
Loading the Jane Austen books from the janeaustenr package
books <- austen_books()Pre-processing the text (a bit quick and dirty)
# Regular expression to identify where new chapters begin
chapter_regex <- "((Chapter|CHAPTER|VOLUME) (\\d+|[IXVL])+)"
# Pre-processing
books <- books %>%
dplyr::group_by(book) %>%
# Each book into one long string:
dplyr::summarise(Text = paste(text, collapse = " "), .groups = "drop_last") %>%
# Insert placeholder at beginning of each chapter
mutate(Text = str_replace_all(Text, chapter_regex, "NEW_CHAPTER\\1")) %>%
# Replace double space with two newlines (to restore structure of the text):
mutate(Text = stringr::str_replace_all(Text, " ", "\n\n")) %>%
# Split each book into a character vector (one element is one chapter):
mutate(Text = stringi::stri_split_regex(Text, "NEW_CHAPTER")) %>%
# Remove first element (book title), so the books start with Chapter 1
mutate(Text = lapply(Text, function(x) x[-1]))
# The result is a data frame with one row for each book.
# The "Text" column is a list of character vectors
# The "book" column is the name of the book
# From one row per book to one row per chapter
books <- tidyr::unnest(books, Text)Creating corporaexplorerobject of the Jane Austen books
When we first have a data frame with text and metadata (in this case just book title), creating a “corporaexplorerobject” for exploration is very simple:
# As this is a corpus which is not organised by date,
# we set `date_based_corpus` to `FALSE`.
# Because we want to organise our exploration around Jane Austen's books,
# we pass `"book"` to the `grouping_variable` argument.
jane_austen <- prepare_data(
dataset = books,
date_based_corpus = FALSE,
grouping_variable = "book"
)